
What is SSL?
SSL (Secure Sockets Layer) is a protocol used in the Internet to provide secure end-to-end communication and client and server authentication. It is widely used in e-commerce and Internet banking. SSL relies on three different cryptographic algorithms. The first algorithm is a key-exchange algorithm such as RSA, DHE, or DSA. These algorithms provide a secure way to exchange the key even when eavesdroppers can look at all communication between a server and clients. The second one is a symmetric cipher that uses the previously-negotiated key such as AES, DES, 3DES, or RC4. These algorithms provide encryption and decryption of actual data communication. The final algorithm is for authentication such as SHA1 or MD5. These algorithms are used to prevent messages from tampering with providing small secure hash values of the messages.
GPU as an SSL accelerator
Recently, scientists and engineers started exploring possibility of using GPUs (Graphics Processing Units) in massive data processing other than graphics workloads. GPUs are heavily used for HPC (high performance computing) or many computation-intensive applications.
Some of the early works also find that GPU is useful for accelerating cryptographic computation such as AES, SHA1, and RSA. Although GPU's high computation capacity delivers higher throughput compared to that of CPU, accelerating SSL poses further challenges due to interactive nature of network applications. GPU's high computation power comes from massive number of small cores, and each core is not as fast as CPU cores. Thus, fully exploitation of the GPU's power requires parallel processing of many independent operations and may end up increasing response time, which is not acceptable in the interactive network applications.
In this work, we carefully design and implement RSA, AES, and HMAC-SHA1 algorithms in GPU, and show that GPUs can perform cryptographic operations much faster than CPUs and incur small latency enough to be used in the interactive network applications. Below we show throughput and latency of our implementation using NVIDIA GTX580. We also show the performance of a core of the Intel X5650 CPU as a reference.
RSA throughput on GTX580
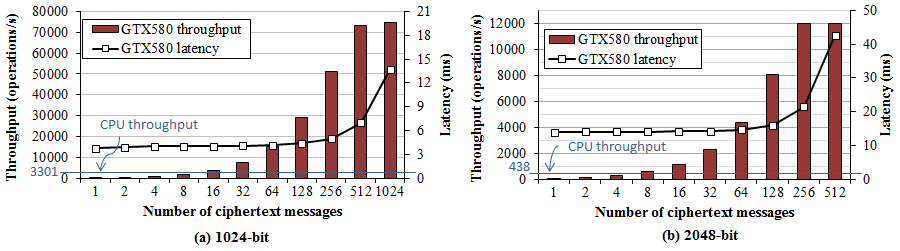
In Figure 1, bars represents the throughput of the NVIDIA GTX580 by varying the number of messages in a batch, and black line represent the processing time of a batch. Blue line represents the performance of a core of the Intel X5650. We observe that the peak throughput of the GTX580 is over 20 CPU cores, reaching 75K and 12K operations per seconds for 1024-bit and 2048-bit respectively. On the other hand, processing a single message is much slower than a single CPU core. The latency for peak throughput is around 10 mili-seconds, and it is low enough for network applications.
RSA decryption is the major bottleneck at the SSL server side, as every new connection will require RSA decryption to exchange the secret key. High-end CPU can only perform around three thousands RSA decryptions per seconds, while a single core can easily handle over 10K plain TCP sessions per seconds. Given that the single GPU can perform RSA computation of over 20x CPU cores, offloading the RSA computation GPU can significantly enhance the SSL performance at a very low cost.
AES throughput on GTX580
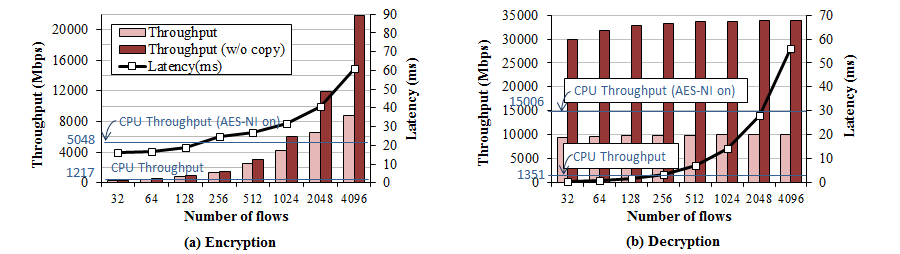
We measure AES performance by varying number of messages in a batch. We use 16KB message which is the maximum record size in the SSL protocol. For AES operations, all the data is copied from the host memory to graphics card's memory, processed in it, and copied back to the host memory. As a reference we also plot the throughput when there's no data copy in the darker bars. In this case, we assume that data is already placed in the GPU, and we do not copy the results back to eliminate the copy portion of processing.
We observe that a single GTX580 performs 9Gbps of AES encryption, and 10Gbps of AES decryption. AES encryption throughput for 32 messages in a batch is very low while AES decryption throughput is almost the maximum even with 32 messages. This is because AES-CBC mode can be parallelized at the 16-byte block level for the decryption while encryption cannot be parallelized due to the dependency between blocks. If we compare the performance against the Intel X5650 CPU, the GTX580 achieves the throughput of approximately seven CPU cores. Recent Intel CPU has a fature called AES-NI that accelerates AES processing. A CPU with AES-NI can perform 5 to 10 times faster than a CPU without it. We observe that a single core can perform 5 Gbps and 15 Gbps for encryption and decryption respectively.
Another important to thing to note here is that, the data copy cost is much more expensive than the AES processing cost. Without the data copy, we observe over 20 to 30 Gbps for both encryption and decryption. In the future, Advances in I/O technology such as PCIe 3.0 will mitigate the data copy cost. Integration of GPU and CPU such as AMD's Fusion APU can eliminate the data copy cost. However, this way lose the benefit of large memory bandwidth of GDDR memory used in graphic cards.
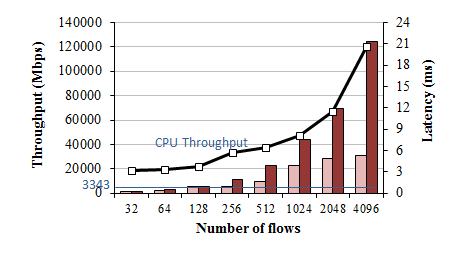
SHA throughput on GTX580
SSLShader Design
We design and implement SSLShader, an SSL reverse proxy, which transparently translates SSL sessions to TCP sessions for back-end servers. The design goal of SSLShader is twofold. First, the performance should scale well to the number of CPU and GPU cores. Second, SSLShader should curb the latency to fit in the interactive environment while improving the throughput at high load. To accomplish those goals, we use following approaches.
- Opportunistic Offloading: To fully exploit GPU's capability, massive parallel processing is essential. In real world network servers, the amount of parallelism varies depending on the number of users, and the benefit of GPU offloading also depends on it. To optimize the performance regardless of the number of users, we implement opportunistic offloading. SSLShader offloads cryptographic operations to GPU only when it can benefit from parallel execution, and otherwise use the CPU to minimize latency.
- NUMA-aware GPU Sharing: In NUMA systems, the communication cost between CPU cores varies greatly, depending on the number of NUMA hops. For high scalability, we design SSLShader to minimize inter-NUMA node communication.
Performance
For performance evaluation, we use a dual Intel Xeon 5650 server equipped with two GTX480 graphics cards.
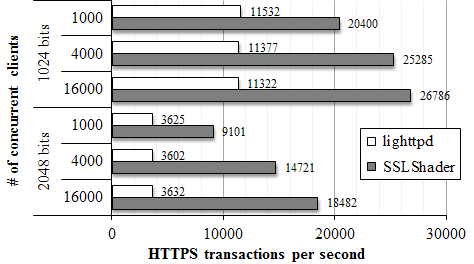
Figure 4 shows the throughput of one byte content transactions by varying the number of simultaneous connections. The results show that SSLShader can improve SSL transaction performance by a factor of two to four.
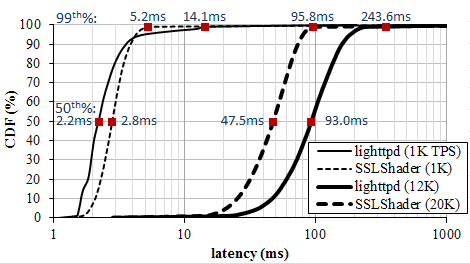
Figure 5 shows latency distribution by varying offered load. SSLShader shows similar latency with lighttpd at the light load, and lower latency under highload. The results shows that opportunistic offloading effectively minimize latency and increase throughput.
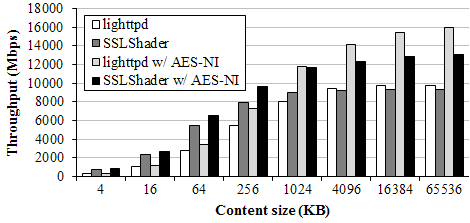
Figure 6 shows bulk transfer throughput compared to lighttpd with OpenSSL. For small transactions under 1MB, SSLShader outperforms lighttpd with or without AES-NI support. For large files SSLShader throughput is lower than that of lighttpd due to data copy overhead of proxying.
Current Status and Future Work
The current bottleneck in SSLShader mainly is in the fact that the Linux kernel's networking stack does not scale well to multiple CPU cores, and that we have data copying overhead due to proxying.
Publications
-
SSLShader: Cheap SSL Acceleration with Commodity Processors
Keon Jang, Sangjin Han, Seungyeop Han, Sue Moon, and KyoungSoo Park.
In proceedings of USENIX NSDI 2011, Boston, MA, March 2011. -
Accelerating SSL with GPUs (2pg extended abstract)
Keon Jang, Sangjin Han, Seungyeop Han, Sue Moon, and KyoungSoo Park.
In proceedings of ACM SIGCOMM 2010 poster session, Delhi, India. September 2010.
Media Coverage
Software
We are in the process of commercializing SSLShader. If you want to license it, contact us and we will tell you whom to contact.
People
Students:
Keon Jang ,
Sangjin Han and
Seungyeop Han
Faculty:
KyoungSoo Park and
Sue Moon
We are collectively reached by our mailing list: tengig at an.kaist.ac.kr.