
What is Kargus?
Intrusion attempts on the Internet have consistently risen in the last few years. As the link bandwidths of large campus & meteropolitan area networks reach 10 Gbps, network administrators have employed high-performance intrusion detection systems (IDSes) that use dedicated network processors and specialized memory to cope with the increasing ingress traffic rates. Unfortunately, the deployment and maintainence costs of such solutions are inevitably high, and the hardware design is often too inflexible to adopt new analysis algorithms.
Kargus is a highly-scalable software-based IDS that runs on commodity PCs and its performance is comparable to hardware-based IDSes. It effectively exploits the potentials of modern hardware innovations such as multicore CPUs, heterogeneous GPUs and multi-queue interface of NICs that drives its monitoring rate by up to 33 Gbps in real time.
Kargus Design
Kargus is a signature-based NIDS that is compatible with Snort. In a typical signature-based IDS, a packet goes through the sequence of modules as illustrated in Figure 1.

After packet capturing, the packet is passed through the preprocessing stage that determines the type of packet (based on packet headers) and identifies the flow corresponding to it. It then passes through the attack signature detection engine. The detection engine is a two-phase analyzer. In the first phase (Multi-string Pattern Matching), the entire payload is scanned to match simple attack strings from the signature library of the IDS. If a packet includes one or more potential attack strings, the second phase (Rule Options Evaluation) matches its payload against a full attack signature that may contain regular expressions or other rule options. Snort uses the Aho-Corasick algorithm to match attack strings while the regular expressions are based on Perl-Compatible Regular Expressions (PCRE).
Kargus improves the performance of an existing software-based IDS by batch processing and exploiting the parallelism in modern computing hardware. Specifically, it benefits from following design choices.
- High-performance packet acquisition: Kargus uses the I/O engine (PSIO) from the PacketShader software router. PSIO boosts the packet RX performance by processing multiple packets at a batch. It allocates a large contiguous kernel buffer per each RX queue at driver initialization and moves multiple packets from a RX queue to the corresponding userspace buffer in a batch (thus avoiding frequent kernel/user context switches). When the packets are consumed by the user application, it reuses the same buffer for the next incoming packets, eliminating the need to deallocate the buffer.
- Multi-threaded parallel execution: Kargus runs multiple IDS engines that are each pinned to a mutually exclusive CPU core to promote parallelization and prevent potential cache bouncing. Each thread shares a common address space that facilitates space-efficient GPU-based pattern matching as all the threads use a single 'context' to communicate with the GPU, consequently sharing common Aho-Corasick state machines across all engines.
- Extensive function call batching: Each Kargus engine passes packets in batches to amortize the per-packet analyzing cost, which greatly improves the performance of small packet processing.
- GPU-based pattern matching & PCRE
evaluation: Kargus employs the GPU in phase 1 of
the pattern matching only when the IDS is under heavy
stress. A modern GPU hosts hundreds of processing
cores and follows the Single Instruction Multiple
Threads
(SIMT)
model that is ideal for memory-intensive parallel
pattern matching.
GPU is also used for evaluating PCREs that can be converted to their corresponding DFAs (those PCREs that don't produce state explosions during DFA conversions via Thompson's algorithm and subset construction algorithm). - Load Balancing between CPU & GPU: Kargus implements an intelligent load-balancing algorithm under which the packets are opportunistically passed to the GPU. That is, if the incoming traffic rate for a given time interval is low enough that the CPUs can handle it, the packets are not passed to the GPU. This prevents excessive power consumption of the machine.
Key Optimizations
We show the results for a few key optimization techniques that we applied. The reader is recommended to refer to the paper for more details.
Aho-Corasick matching & PCRE evaluation throughputs on an NVIDIA GTX580 card
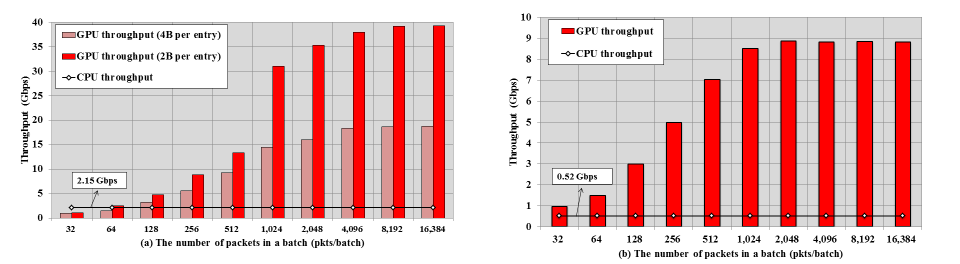
Figure 2(a) shows the performance of multi-string pattern matching for a single Intel X5680 CPU core and the GPU device with 1518B packets. The GPU performance increases as the batch size grows since more GPU processing cores are utilized with a larger batch size. We find that reducing the Aho-Corasick DFA table entry to 2 bytes from 4 bytes almost doubles the throughput, which confirms that the GPU memory access is the main bottleneck.
Figure 2(b) shows the performance of PCRE matching. The performance of GPU PCRE matching is not comparable to that of multi-string matching even if it implements the same DFA transitions. This is because PCRE matching requires each packet to follow a different PCRE DFA table in most cases. In contrast, multi-string matching shares the same Aho-Corasick DFA table across all threads in most cases, benefiting from lower memory contention.
Effects of Batched Execution
Kargus ensures that packets are passed from one function to another in a batch, where only when a packet needs to take a different path, it diverges on the function call. When an IDS engine thread in Kargus reads a batch of packets from RX queues, it passes the batch to these functions as an argument instead of calling them repeatedly for each packet. This effectively reduces the per-packet function call overhead from the packet acquisition module to the rule option evaluation module. The advantage of the function call batching becomes pronounced especially for small packets.
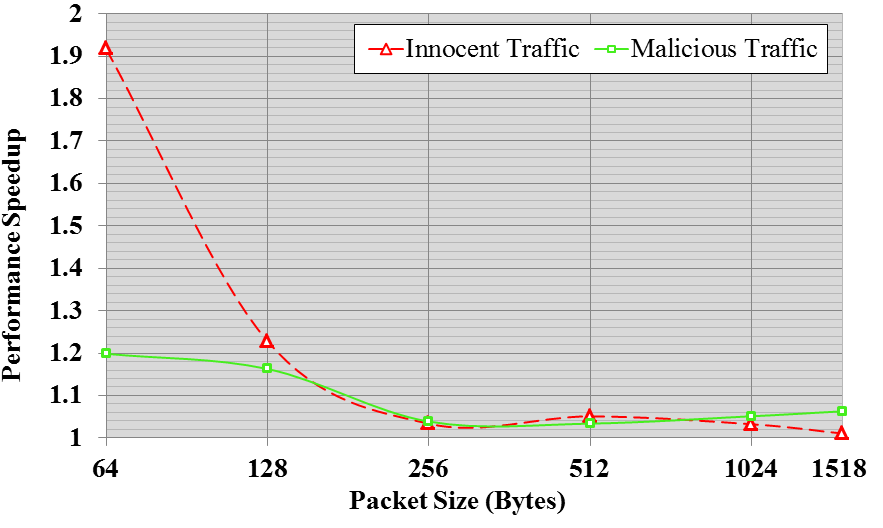
We generate innocent and malicious traffic at the rate of 40 Gbps.
Performance
For performance evaluation, we use a dual hexanode Intel Xeon 5680 3.33 GHz server equipped with two NVIDIA GTX580 graphics cards. Our platform has 24 GB RAM and has 2 dual-port Intel 82599 10 Gbps NICs.
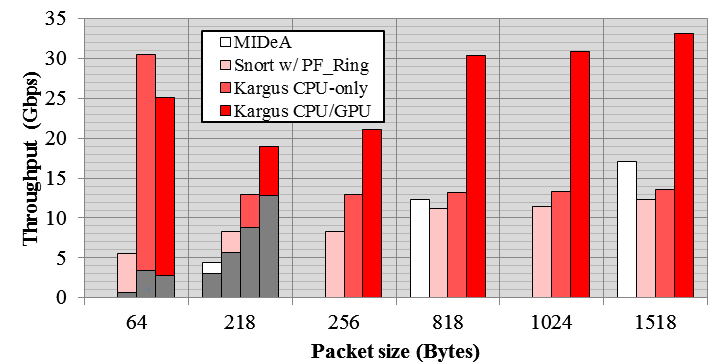
Figure 4 shows how the performance of Kargus compares with other IDSes. We note that the throughput of Kargus is far higher at 64B packets when compared with packets of larger sizes. This is because the majority of the data is packet headers that are not passed to the analyzing engine. The shaded portion at 64B represents the performance of analyzed TCP payloads, and we can see that the portion increases at 128B.
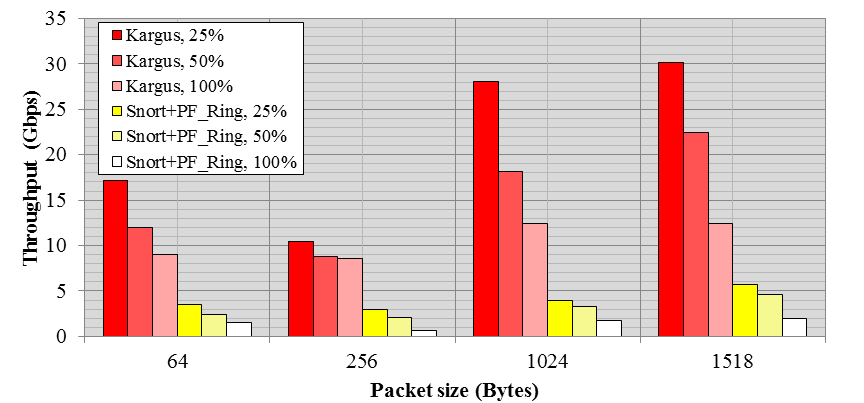
Figure 5 shows the throughputs of Kargus when we control the portion of attack packets by 25%, 50%, and 100%, for various packet sizes. In this case, the PCRE rules are triggered as part of rule option evaluation, and it significantly increases the pattern matching overheads. As expected, the performance degrades as the packet size becomes smaller as well as the attack portion increases.
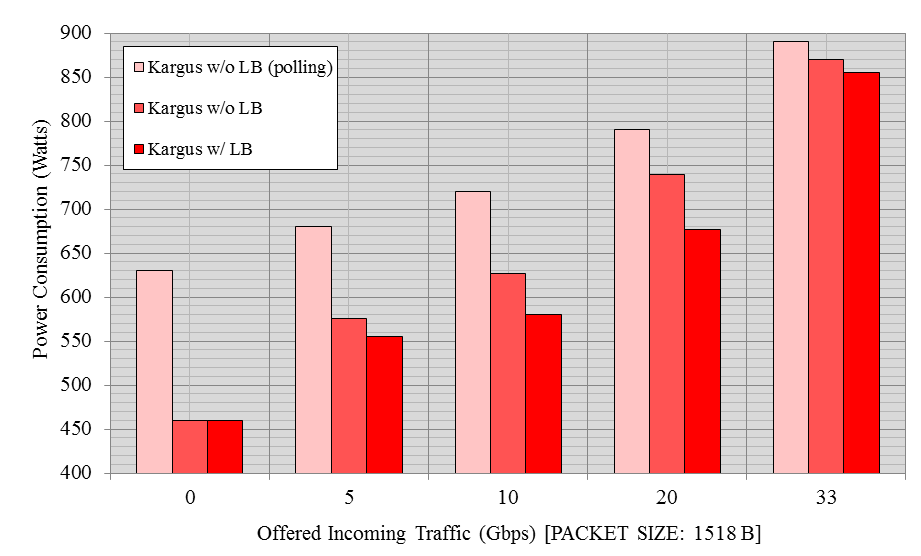
Figure 6 shows the energy efficiency of Kargus when it opportunistically offloads packets to the GPU. We plot the power consumption for different incoming rates. The packet size is set to 1518B. We compare (i) Kargus with dynamic GPU-offloading, (ii) Kargus without load balancing (unconditional GPU offloading), and (iii) Kargus without load balancing with the PSIO set to polling mode. Kargus at polling mode keeps the CPU constantly busy. Therefore, it shows the highest power consumption.
Current Status and Future Work
Kargus currently provides support for TCP/HTTP protocol suite. We are working on expanding support for a broader range of protocols.
Publications
- Kargus: A Highly-scalable
Software-based Intrusion Detection System
Muhammad Jamshed, Jihyung Lee, Sangwoo Moon, Insu Yun, Deokjin Kim, Sungryoul Lee, Yung Yi and KyoungSoo Park. In Proceedings of the 19th ACM Conference on Computer and Communications Security (CCS '12), Raleigh, NC, USA, on Oct, 2012. Slides: [pptx] [pdf]
Press Coverage
Software
Kargus is currently being commercialized and tech-transferred to
industry. Please contact us if you're interested in licensing it
and we'll redirect you to the right person.
People
Students: Muhammad Asim Jamshed,
Jihyung Lee,
Sangwoo Moon
, and Insu Yun
Faculty: Yung Yi and
KyoungSoo Park
We are collectively reached by our mailing list: fast-ids@list.ndsl.kaist.edu.
Last modified: Fri, Nov 30th, 2012 / Networked & Distributed Computing Systems Lab & Laboratory of Network Architecture, Design, and Analysis