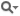device_context Class Reference
#include <device_context.hh>
Detailed Description
device_context class.
help managing cuda stream state and memory allocation
Member Function Documentation
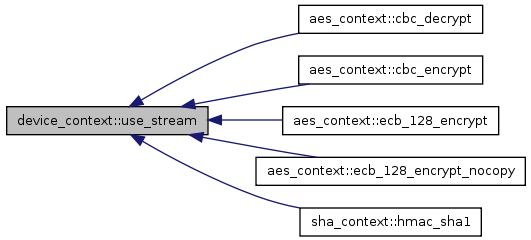
| void device_context::clear_checkbits |
( |
const unsigned |
stream_id, |
|
|
const unsigned |
num_blks | |
|
) |
| | |
Reset checkbits to 0 for new kernel execution.
- Parameters:
-
| stream_id | Index of stream. If initilized to 0 stream then 0, otherwise from 1 to number of streams initialized. |
| num_blks | Length in bytes to be reset to 0. It should be same as the number of cuda blocks for kernel execution. |
00140 {
00141 assert(stream_id >= 0 && stream_id <= nstream_);
00142 assert((stream_id == 0) ^ (nstream_ > 0));
00143 assert(num_blks >= 0 && num_blks <= MAX_BLOCKS);
00144
00145 stream_ctx_[stream_id].num_blks = num_blks;
00146 volatile uint8_t *checkbits = stream_ctx_[stream_id].checkbits;
00147 for (unsigned i = 0; i < num_blks; i++)
00148 checkbits[i] = 0;
00149 stream_ctx_[stream_id].finished = false;
00150 }
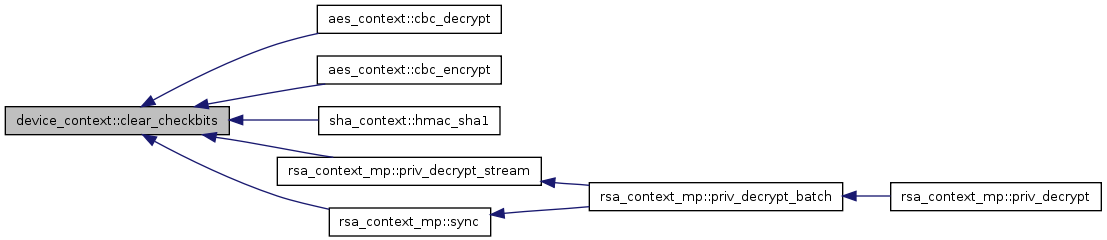
| cuda_mem_pool * device_context::get_cuda_mem_pool |
( |
const unsigned |
stream_id |
) |
|
Retrieves device memory pool to allocate memory for stream
- Parameters:
-
| stream_id | index of stream 1 to 16 for streams, and 0 for default stream |
- Returns:
00154 {
00155 assert(stream_id >= 0 && stream_id <= nstream_);
00156 assert((stream_id == 0) ^ (nstream_ > 0));
00157
00158 return &stream_ctx_[stream_id].pool;
00159 }
| uint8_t * device_context::get_dev_checkbits |
( |
const unsigned |
stream_id |
) |
|
Retreive the buffer storing the kernel execution finish check bits.
This buffer is used in sync function to check whether the kernel has finished or not. Executed kernel will set this each byte to 1 at the end of execution. We use checkbits instead of cudaStreamSynchronize because Calling cudaStreamSynchronize to a stream will block other streams from launching new kernels and it won't return before all previos launched kernel start execution according to CUDA manual 3.2. We use host mapped memory to avoid calling cudaStreamSyncrhonize and check whether kernel execution has finished or not so that multiple stream can run simultaneously without blocking others.
- Parameters:
-
| stream_id | Index of stream. If initilized to 0 stream then 0, otherwise from 1 to number of streams initialized. |
- Returns:
- pointer to a buffer
00133 {
00134 assert(stream_id >= 0 && stream_id <= nstream_);
00135 assert((stream_id == 0) ^ (nstream_ > 0));
00136
00137 return stream_ctx_[stream_id].checkbits_d;
00138 }
| uint64_t device_context::get_elapsed_time |
( |
const unsigned |
stream_id |
) |
[inline] |
Retrieves the time took for the processing in the stream It will only return correct value when all the processing in the stream is finished and state of the stream is back to READY again.
- Parameters:
-
| stream_id | index of stream 1 to 16 for streams, and 0 for default stream |
- Returns:
00147 {
00148 assert(0 <= stream_id && stream_id <= nstream_);
00149 assert((stream_id == 0) ^ (nstream_ > 0));
00150 return stream_ctx_[stream_id].end_usec - stream_ctx_[stream_id].begin_usec;
00151 }
| enum STATE device_context::get_state |
( |
const unsigned |
stream_id |
) |
|
retrieve the state of the stream
- Parameters:
-
| stream_id | Index of stream. If initilized to 0 stream then 0, otherwise from 1 to number of streams initialized. |
- Returns:
- Current state of the stream
00117 {
00118 assert(stream_id >= 0 && stream_id <= nstream_);
00119 assert((stream_id == 0) ^ (nstream_ > 0));
00120
00121 return stream_ctx_[stream_id].state;
00122 }
| cudaStream_t device_context::get_stream |
( |
const unsigned |
stream_id |
) |
|
Retrieves cudaStream from stream index.
- Parameters:
-
| stream_id | Index of stream. If initilized to 0 stream then 0, otherwise from 1 to number of streams initialized. |
- Returns:
- cudaStream
00125 {
00126 assert(stream_id >= 0 && stream_id <= nstream_);
00127 assert((stream_id == 0) ^ (nstream_ > 0));
00128
00129 return stream_ctx_[stream_id].stream;
00130 }
| bool device_context::init |
( |
const unsigned long |
size, |
|
|
const unsigned |
nstream | |
|
) |
| | |
Initialize device context. This function will allocate device memory and streams.
- Parameters:
-
| size | Total amount of memory per stream |
| nstream | Number of streams to use. Maximum 16 and minimum is 0. Use 0 if you want use default stream only. Be aware that using a single stream and no stream is different. For more information on how they differ, refer to CUDA manual. |
- Returns:
- true when succesful, false otherwise
00036 {
00037 void *ret = NULL;
00038 assert(nstream >= 0 && nstream <= MAX_STREAM);
00039 assert(init_ == false);
00040 init_ = true;
00041
00042 nstream_ = nstream;
00043
00044 if (nstream_ > 0) {
00045 for (unsigned i = 1; i <= nstream; i++) {
00046 cutilSafeCall(cudaStreamCreate(&stream_ctx_[i].stream));
00047
00048 if (!stream_ctx_[i].pool.init(size))
00049 return false;
00050 stream_ctx_[i].state = READY;
00051
00052 cutilSafeCall(cudaHostAlloc(&ret, MAX_BLOCKS, cudaHostAllocMapped));
00053 stream_ctx_[i].checkbits = (uint8_t*)ret;
00054 cutilSafeCall(cudaHostGetDevicePointer((void **)&stream_ctx_[i].checkbits_d, ret, 0));
00055 }
00056 } else {
00057 stream_ctx_[0].stream = 0;
00058 if (!stream_ctx_[0].pool.init(size))
00059 return false;
00060
00061 stream_ctx_[0].state = READY;
00062
00063 cutilSafeCall(cudaHostAlloc(&ret, MAX_BLOCKS, cudaHostAllocMapped));
00064 stream_ctx_[0].checkbits = (uint8_t*)ret;
00065 cutilSafeCall(cudaHostGetDevicePointer((void **)&stream_ctx_[0].checkbits_d, ret, 0));
00066 }
00067 return true;
00068 }
| void device_context::set_state |
( |
const unsigned |
stream_id, |
|
|
const STATE |
state | |
|
) |
| | |
Set the state of the stream. States indicates what is the current operation on-going.
- Parameters:
-
| stream_id | Index of stream. If initilized to 0 stream then 0, otherwise from 1 to number of streams initialized. |
| state | Describe the current state of stream. Currently there are three different states: READY, WAIT_KERNEL, WAIT_COPY. |
00099 {
00100 assert(stream_id >= 0 && stream_id <= nstream_);
00101 assert((stream_id == 0) ^ (nstream_ > 0));
00102
00103 if (state == READY) {
00104 stream_ctx_[stream_id].end_usec = get_now();
00105 stream_ctx_[stream_id].num_blks = 0;
00106 stream_ctx_[stream_id].pool.reset();
00107 } else if (state == WAIT_KERNEL) {
00108 stream_ctx_[stream_id].begin_usec = get_now();
00109 stream_ctx_[stream_id].finished = false;
00110 } else if (state == WAIT_COPY) {
00111 stream_ctx_[stream_id].finished = false;
00112 }
00113 stream_ctx_[stream_id].state = state;
00114 }
| bool device_context::sync |
( |
const unsigned |
stream_id, |
|
|
const bool |
block = true | |
|
) |
| | |
Check whether current operation has finished.
- Parameters:
-
| stream_id | Index of stream. If initilized to 0 stream then 0, otherwise from 1 to number of streams initialized. |
| block | Wait for current operation to finish. true by default |
- Returns:
- true if stream is idle, and false if data copy or execution is in progress
00071 {
00072 assert(stream_id >= 0 && stream_id <= nstream_);
00073 assert((stream_id == 0) ^ (nstream_ > 0));
00074 if (!block) {
00075 if (stream_ctx_[stream_id].finished)
00076 return true;
00077
00078 if (stream_ctx_[stream_id].state == WAIT_KERNEL && stream_ctx_[stream_id].num_blks > 0) {
00079 volatile uint8_t *checkbits = stream_ctx_[stream_id].checkbits;
00080 for (unsigned i = 0; i < stream_ctx_[stream_id].num_blks; i++) {
00081 if (checkbits[i] == 0)
00082 return false;
00083 }
00084 } else if (stream_ctx_[stream_id].state != READY) {
00085 cudaError_t ret = cudaStreamQuery(stream_ctx_[stream_id].stream);
00086 if (ret == cudaErrorNotReady)
00087 return false;
00088 assert(ret == cudaSuccess);
00089 }
00090 stream_ctx_[stream_id].finished = true;
00091 } else {
00092 cudaStreamSynchronize(stream_ctx_[stream_id].stream);
00093 }
00094
00095 return true;
00096 }
| bool device_context::use_stream |
( |
|
) |
[inline] |
Query whether the device context is initialized to use stream or not.
- Returns:
00126 { return (nstream_ != 0); };




 1.6.3
1.6.3