#include <aes_context.hh>
Public Member Functions | |
| aes_context (device_context *dev_ctx) | |
| void | ecb_128_encrypt (const void *memory_start, const unsigned long in_pos, const unsigned long keys_pos, const unsigned long pkt_index_pos, const unsigned long data_size, unsigned char *out, const unsigned long block_count, const unsigned long num_flows, unsigned int stream_id) |
| void | ecb_128_encrypt_nocopy (const void *memory_start, const unsigned long in_pos, const unsigned long keys_pos, const unsigned long pkt_index_pos, const unsigned long data_size, unsigned char *out, const unsigned long block_count, const unsigned long num_flows, unsigned int stream_id) |
| void | cbc_encrypt (const void *memory_start, const unsigned long in_pos, const unsigned long keys_pos, const unsigned long ivs_pos, const unsigned long pkt_offset_pos, const unsigned long tot_in_len, unsigned char *out, const unsigned long num_flows, const unsigned long tot_out_len, const unsigned int stream_id, const unsigned int bits=128) |
| void | cbc_decrypt (const void *memory_start, const unsigned long in_pos, const unsigned long keys_pos, const unsigned long ivs_pos, const unsigned long pkt_index_pos, const unsigned long data_size, unsigned char *out, const unsigned long block_count, const unsigned long num_flows, unsigned int stream_id, const unsigned int bits=128) |
| bool | sync (const unsigned int stream_id, const bool block=true, const bool copy_result=true) |
class aes_context
Interface for AES cipher in GPU. It supports 128-bit CBC-mode encryption/decryptiion, ecb 128 bit encryption.
| aes_context::aes_context | ( | device_context * | dev_ctx | ) |
Constructior.
| dev_ctx | Device context pointer. Device context must be initialized before calling this function. |
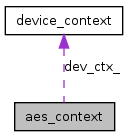
| void aes_context::cbc_decrypt | ( | const void * | memory_start, | |
| const unsigned long | in_pos, | |||
| const unsigned long | keys_pos, | |||
| const unsigned long | ivs_pos, | |||
| const unsigned long | pkt_index_pos, | |||
| const unsigned long | data_size, | |||
| unsigned char * | out, | |||
| const unsigned long | block_count, | |||
| const unsigned long | num_flows, | |||
| unsigned int | stream_id, | |||
| const unsigned int | bits = 128 | |||
| ) |
It executes AES-CBC encryption in GPU.
It only supports 128-bit key length at the moment.
If stream is enabled it will run in non-blocking mode, if not, it will run in blocking mode and the result will be written back to out at the end of function call. This function takes one or more plaintext and returns ciphertext for all of them.
| memory_start | Starting point of input data. | |
| in_pos | Offset of plain texts. All plain texts are gathered in to one big buffer with 16-byte align which is AES block size. | |
| keys_pos | Offset of region that stores keys. | |
| ivs_pos | Offset of region that store IVs. | |
| pkt_index_pos | Offset of region that stores per plain text index for every block. It is used to locate key an IV. | |
| data_size | Total amount of input data. | |
| out | Buffer to store output. | |
| block_count | Total number of blocks in all plain texts. | |
| num_flows | Total number of plain text. | |
| stream_id | Stream index. | |
| bits | key length for AES cipher |
00270 { 00271 assert(bits==128); 00272 assert(dev_ctx_->get_state(stream_id) == READY); 00273 dev_ctx_->set_state(stream_id, WAIT_KERNEL); 00274 00275 unsigned long total_len = block_count * AES_BLOCK_SIZE; 00276 uint8_t *in_d; 00277 uint8_t *keys_d; 00278 uint8_t *ivs_d; 00279 uint16_t *pkt_index_d; 00280 void *memory_d; 00281 unsigned int threads_per_blk = 512; 00282 int num_blks = (block_count + threads_per_blk - 1) / threads_per_blk; 00283 00284 //transfor encrypt key to decrypt key 00285 //basically it generates round key and take the last 00286 //CUDA code will generate the round key in reverse order 00287 for (unsigned i = 0; i < num_flows; i++) { 00288 uint8_t *key = (uint8_t *)memory_start + keys_pos + i * bits / 8; 00289 AES_decrypt_key_prepare(key, key, bits); 00290 } 00291 00292 dev_ctx_->clear_checkbits(stream_id, num_blks); 00293 00294 cuda_mem_pool *pool = dev_ctx_->get_cuda_mem_pool(stream_id); 00295 memory_d = pool->alloc(data_size); 00296 cudaMemcpyAsync(memory_d, 00297 memory_start, 00298 data_size, 00299 cudaMemcpyHostToDevice, 00300 dev_ctx_->get_stream(stream_id)); 00301 00302 streams[stream_id].out_d = (uint8_t*)pool->alloc(total_len); 00303 00304 in_d = (uint8_t *) memory_d + in_pos; 00305 keys_d = (uint8_t *) memory_d + keys_pos; 00306 ivs_d = (uint8_t *) memory_d + ivs_pos; 00307 pkt_index_d = (uint16_t *) ((uint8_t *) memory_d + pkt_index_pos); 00308 00309 assert(bits == 128); 00310 if (dev_ctx_->use_stream() && stream_id > 0) { 00311 AES_cbc_128_decrypt_gpu(in_d, 00312 streams[stream_id].out_d, 00313 keys_d, 00314 ivs_d, 00315 pkt_index_d, 00316 block_count, 00317 dev_ctx_->get_dev_checkbits(stream_id), 00318 threads_per_blk, 00319 dev_ctx_->get_stream(stream_id)); 00320 } else if (stream_id == 0) { 00321 AES_cbc_128_decrypt_gpu(in_d, 00322 streams[stream_id].out_d, 00323 keys_d, 00324 ivs_d, 00325 pkt_index_d, 00326 block_count, 00327 dev_ctx_->get_dev_checkbits(stream_id), 00328 threads_per_blk); 00329 } else { 00330 assert(0); 00331 } 00332 00333 assert(cudaGetLastError() == cudaSuccess); 00334 00335 streams[stream_id].out = out; 00336 streams[stream_id].out_len = total_len; 00337 00338 if (!dev_ctx_->use_stream()) { 00339 sync(stream_id, true); 00340 } 00341 }
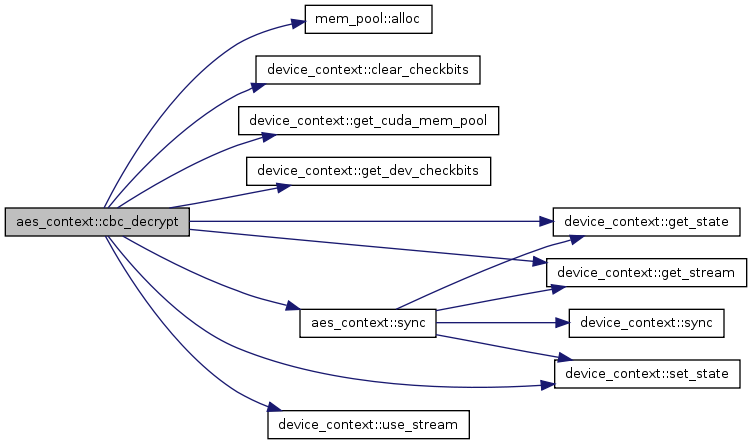
| void aes_context::cbc_encrypt | ( | const void * | memory_start, | |
| const unsigned long | in_pos, | |||
| const unsigned long | keys_pos, | |||
| const unsigned long | ivs_pos, | |||
| const unsigned long | pkt_offset_pos, | |||
| const unsigned long | tot_in_len, | |||
| unsigned char * | out, | |||
| const unsigned long | num_flows, | |||
| const unsigned long | tot_out_len, | |||
| const unsigned int | stream_id, | |||
| const unsigned int | bits = 128 | |||
| ) |
It executes AES-CBC encryption in GPU.
It only supports 128-bit key length at the moment.
If stream is enabled it will run in non-blocking mode, if not, it will run in blocking mode and the result will be written back to out at the end of function call. This function takes one or more plaintext and returns ciphertext for all of them.
| memory_start | Starting point of input data. | |
| in_pos | Offset of plain texts. All plain texts are gathered in to one big buffer with 16-byte align which is AES block size. | |
| keys_pos | Offset of region that stores keys. | |
| ivs_pos | Offset of region that store IVs. | |
| pkt_offset_pos | Offset of region that stores position of the beginning of each plain text. | |
| tot_in_len | Total amount of input data plus meta data. | |
| out | Buffer to store output. | |
| block_count | Total number of blocks in all plain texts. | |
| num_flows | Total number of plain text. | |
| tot_out_len | Total amount of output length. | |
| stream_id | Stream index. | |
| bits | key length for AES cipher |
00034 { 00035 assert(bits == 128); 00036 assert(dev_ctx_->get_state(stream_id) == READY); 00037 dev_ctx_->set_state(stream_id, WAIT_KERNEL); 00038 00039 /* Allocate memory on device */ 00040 uint8_t *in_d; 00041 uint8_t *keys_d; 00042 uint8_t *ivs_d; 00043 uint32_t *pkt_offset_d; 00044 void *memory_d; 00045 00046 //Calculate # of cuda blks required 00047 unsigned int threads_per_blk = THREADS_PER_BLK; 00048 int num_blks = (num_flows + threads_per_blk - 1) / threads_per_blk; 00049 cuda_mem_pool *pool = dev_ctx_->get_cuda_mem_pool(stream_id); 00050 00051 memory_d = pool->alloc(tot_in_len); 00052 cudaMemcpyAsync(memory_d, memory_start, tot_in_len, 00053 cudaMemcpyHostToDevice, dev_ctx_->get_stream(stream_id)); 00054 00055 dev_ctx_->clear_checkbits(stream_id, num_blks); 00056 00057 streams[stream_id].out_d = (uint8_t*)pool->alloc(tot_out_len); 00058 00059 in_d = (uint8_t *) memory_d + in_pos; 00060 keys_d = (uint8_t *) memory_d + keys_pos; 00061 ivs_d = (uint8_t *) memory_d + ivs_pos; 00062 pkt_offset_d = (uint32_t *) ((uint8_t *)memory_d + pkt_offset_pos); 00063 00064 /* Call cbc kernel function to do encryption */ 00065 if (dev_ctx_->use_stream()) { 00066 AES_cbc_128_encrypt_gpu(in_d, 00067 streams[stream_id].out_d, 00068 pkt_offset_d, 00069 keys_d, 00070 ivs_d, 00071 num_flows, 00072 dev_ctx_->get_dev_checkbits(stream_id), 00073 threads_per_blk, 00074 dev_ctx_->get_stream(stream_id)); 00075 } else { 00076 AES_cbc_128_encrypt_gpu(in_d, 00077 streams[stream_id].out_d, 00078 pkt_offset_d, 00079 keys_d, 00080 ivs_d, 00081 num_flows, 00082 dev_ctx_->get_dev_checkbits(stream_id), 00083 threads_per_blk); 00084 00085 } 00086 00087 assert(cudaGetLastError() == cudaSuccess); 00088 00089 streams[stream_id].out = out; 00090 streams[stream_id].out_len = tot_out_len; 00091 00092 /* Copy data back from device to host */ 00093 if (!dev_ctx_->use_stream()) { 00094 sync(stream_id); 00095 } 00096 }
| void aes_context::ecb_128_encrypt | ( | const void * | memory_start, | |
| const unsigned long | in_pos, | |||
| const unsigned long | keys_pos, | |||
| const unsigned long | pkt_index_pos, | |||
| const unsigned long | data_size, | |||
| unsigned char * | out, | |||
| const unsigned long | block_count, | |||
| const unsigned long | num_flows, | |||
| unsigned int | stream_id | |||
| ) |
It executes AES-ECB-128 encryption in GPU. If stream is enabled it will run in non-blocking mode, if not, it will run in blocking mode and the result will be written back to out at the end of function call. This function takes one or more plaintext and returns ciphertext for all of them.
| memory_start | Starting point of input data. | |
| in_pos | Offset of plain texts. All plain texts are gathered in to one big buffer with 16-byte align which is AES block size. | |
| keys_pos | Offset of region that stores keys. | |
| pkt_index_pos | Offset of region that stores per plain text index for every block. | |
| data_size | Total amount of input data. | |
| out | Buffer to store output. | |
| block_count | Total number of blocks in all plain texts. | |
| num_flows | Total number of plain text. | |
| stream_id | Stream index. |
00156 { 00157 assert(dev_ctx_->get_state(stream_id) == READY); 00158 00159 unsigned long total_len = block_count * AES_BLOCK_SIZE; 00160 uint8_t *in_d; 00161 uint8_t *keys_d; 00162 uint16_t *pkt_index_d; 00163 void * memory_d; 00164 00165 cuda_mem_pool *pool = dev_ctx_->get_cuda_mem_pool(stream_id); 00166 memory_d = pool->alloc(data_size); 00167 cudaMemcpyAsync(memory_d, memory_start, data_size, 00168 cudaMemcpyHostToDevice, dev_ctx_->get_stream(stream_id)); 00169 00170 streams[stream_id].out_d = (uint8_t *) pool->alloc(total_len); 00171 00172 in_d = (uint8_t *) memory_d + in_pos; 00173 keys_d = (uint8_t *) memory_d + keys_pos; 00174 pkt_index_d = (uint16_t *) ((uint8_t *) memory_d + pkt_index_pos); 00175 00176 unsigned int threads_per_blk = THREADS_PER_BLK; 00177 00178 if (dev_ctx_->use_stream()) 00179 AES_ecb_128_encrypt_gpu(in_d, 00180 streams[stream_id].out_d, 00181 keys_d, 00182 pkt_index_d, 00183 block_count, 00184 threads_per_blk, 00185 dev_ctx_->get_stream(stream_id)); 00186 else 00187 AES_ecb_128_encrypt_gpu(in_d, 00188 streams[stream_id].out_d, 00189 keys_d, 00190 pkt_index_d, 00191 block_count, 00192 threads_per_blk); 00193 00194 dev_ctx_->set_state(stream_id, WAIT_KERNEL); 00195 00196 streams[stream_id].out = out; 00197 streams[stream_id].out_len = total_len; 00198 00199 if (!dev_ctx_->use_stream()) { 00200 sync(stream_id); 00201 } 00202 }

| void aes_context::ecb_128_encrypt_nocopy | ( | const void * | memory_start, | |
| const unsigned long | in_pos, | |||
| const unsigned long | keys_pos, | |||
| const unsigned long | pkt_index_pos, | |||
| const unsigned long | data_size, | |||
| unsigned char * | out, | |||
| const unsigned long | block_count, | |||
| const unsigned long | num_flows, | |||
| unsigned int | stream_id | |||
| ) |
It executes AES-ECB-128 encryption in GPU. This function differs from ecb_128_encrypt in that it will not involve any data copy from/to GPU. This was intended to measure purely AES computation performance using GPU.
| memory_start | Starting point of input data. | |
| in_pos | Offset of plain texts. All plain texts are gathered in to one big buffer with 16-byte align which is AES block size. | |
| keys_pos | Offset of region that stores keys. | |
| pkt_index_pos | Offset of region that stores per plain text index for every block. | |
| data_size | Total amount of input data. | |
| out | Buffer to store output. | |
| block_count | Total number of blocks in all plain texts. | |
| num_flows | Total number of plain text. | |
| stream_id | Stream index. |
00213 { 00214 assert(dev_ctx_->get_state(stream_id) == READY); 00215 00216 unsigned long total_len = block_count * AES_BLOCK_SIZE; 00217 uint8_t *in_d; 00218 uint8_t *keys_d; 00219 uint16_t *pkt_index_d; 00220 void * memory_d; 00221 00222 cuda_mem_pool *pool = dev_ctx_->get_cuda_mem_pool(stream_id); 00223 00224 memory_d = pool->alloc(data_size); 00225 streams[stream_id].out_d = (uint8_t*)pool->alloc(total_len); 00226 in_d = (uint8_t *) memory_d + in_pos; 00227 keys_d = (uint8_t *) memory_d + keys_pos; 00228 pkt_index_d = (uint16_t *) ((uint8_t *) memory_d + pkt_index_pos); 00229 00230 unsigned int threads_per_blk = THREADS_PER_BLK; 00231 00232 if (dev_ctx_->use_stream()) 00233 AES_ecb_128_encrypt_gpu(in_d, 00234 streams[stream_id].out_d, 00235 keys_d, 00236 pkt_index_d, 00237 block_count, 00238 threads_per_blk, 00239 dev_ctx_->get_stream(stream_id)); 00240 else 00241 AES_ecb_128_encrypt_gpu(in_d, 00242 streams[stream_id].out_d, 00243 keys_d, pkt_index_d, 00244 block_count, 00245 threads_per_blk); 00246 00247 assert(cudaGetLastError() == cudaSuccess); 00248 dev_ctx_->set_state(stream_id, WAIT_KERNEL); 00249 00250 streams[stream_id].out = out; 00251 streams[stream_id].out_len = total_len; 00252 00253 if (!dev_ctx_->use_stream()) { 00254 sync(stream_id); 00255 } 00256 }

| bool aes_context::sync | ( | const unsigned int | stream_id, | |
| const bool | block = true, |
|||
| const bool | copy_result = true | |||
| ) |
Synchronize/query the execution on the stream. This function can be used to check whether the current execution on the stream is finished or also be used to wait until the execution to be finished.
| stream_id | Stream index. | |
| block | Wait for the execution to finish or not. true by default. | |
| copy_result | If false, it will not copy result back to CPU. |
00101 { 00102 if (block) { 00103 dev_ctx_->sync(stream_id, true); 00104 if (copy_result && dev_ctx_->get_state(stream_id) == WAIT_KERNEL) { 00105 cutilSafeCall(cudaMemcpyAsync(streams[stream_id].out, 00106 streams[stream_id].out_d, 00107 streams[stream_id].out_len, 00108 cudaMemcpyDeviceToHost, 00109 dev_ctx_->get_stream(stream_id))); 00110 dev_ctx_->set_state(stream_id, WAIT_COPY); 00111 dev_ctx_->sync(stream_id, true); 00112 dev_ctx_->set_state(stream_id, READY); 00113 } else if (dev_ctx_->get_state(stream_id) == WAIT_COPY) { 00114 dev_ctx_->set_state(stream_id, READY); 00115 } 00116 return true; 00117 } else { 00118 if (!dev_ctx_->sync(stream_id, false)) 00119 return false; 00120 00121 if (dev_ctx_->get_state(stream_id) == WAIT_KERNEL) { 00122 //if no need for data copy 00123 if (!copy_result) { 00124 dev_ctx_->set_state(stream_id, READY); 00125 return true; 00126 } 00127 00128 cutilSafeCall(cudaMemcpyAsync(streams[stream_id].out, 00129 streams[stream_id].out_d, 00130 streams[stream_id].out_len, 00131 cudaMemcpyDeviceToHost, 00132 dev_ctx_->get_stream(stream_id))); 00133 dev_ctx_->set_state(stream_id, WAIT_COPY); 00134 00135 } else if (dev_ctx_->get_state(stream_id) == WAIT_COPY) { 00136 dev_ctx_->set_state(stream_id, READY); 00137 return true; 00138 } else if (dev_ctx_->get_state(stream_id) == READY) { 00139 return true; 00140 } else { 00141 assert(0); 00142 } 00143 } 00144 return false; 00145 }
 1.6.3
1.6.3