sha_context Class Reference
#include <sha_context.hh>
Public Member Functions |
| | sha_context (device_context *dev_ctx) |
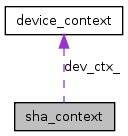
| void | hmac_sha1 (const void *memory_start, const unsigned long in_pos, const unsigned long keys_pos, const unsigned long pkt_offset_pos, const unsigned long lengths_pos, const unsigned long data_size, unsigned char *out, const unsigned long num_flows, unsigned int stream_id) |
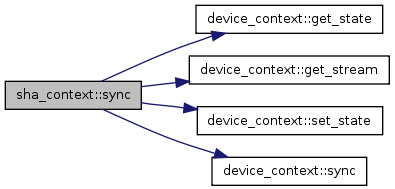
| bool | sync (const unsigned int stream_id, const bool block=true, const bool copy_result=true) |
Detailed Description
class sha_context
Interface for HMAC-SHA1 in GPU.
Constructor & Destructor Documentation
Constructior.
- Parameters:
-
| dev_ctx | Device context pointer. Device context must be initialized before calling this function. |
00009 {
00010 for (unsigned i = 0; i <MAX_STREAM; i++) {
00011 streams[i].out = 0;
00012 streams[i].out_d = 0;
00013 streams[i].out_len = 0;
00014 }
00015 dev_ctx_ = dev_ctx;
00016 }
Member Function Documentation
| void sha_context::hmac_sha1 |
( |
const void * |
memory_start, |
|
|
const unsigned long |
in_pos, |
|
|
const unsigned long |
keys_pos, |
|
|
const unsigned long |
pkt_offset_pos, |
|
|
const unsigned long |
lengths_pos, |
|
|
const unsigned long |
data_size, |
|
|
unsigned char * |
out, |
|
|
const unsigned long |
num_flows, |
|
|
unsigned int |
stream_id | |
|
) |
| | |
It executes hmac_sha1 in GPU. If stream is enabled it will run in non-blocking mode, if not, it will run in blocking mode and the result will be written back to out at the end of function call. This function takes one or more data and returns HMAC-SHA1 value for all of them.
- Parameters:
-
| memory_start | Starting point of input data. All input data should be be packed in to single continous region before making call to this function. |
| in_pos | Offset of plain texts. |
| keys_pos | Offset of region that stores HHAC keys. |
| pkt_offset_pos | Offset of region that stores position of each plain text. |
| lengths_pos | Offset of region that stores length of each plain text. |
| data_size | Total amount of input data. |
| out | Buffer to store output. |
| num_flows | Number of plain texts to be hashed. |
| stream_id | Stream index. |
00031 {
00032 assert(dev_ctx_->get_state(stream_id) == READY);
00033 dev_ctx_->set_state(stream_id, WAIT_KERNEL);
00034 cuda_mem_pool *pool = dev_ctx_->get_cuda_mem_pool(stream_id);
00035 void *memory_d = pool->alloc(data_size);;
00036
00037
00038 cudaMemcpyAsync(memory_d,
00039 memory_start,
00040 data_size,
00041 cudaMemcpyHostToDevice,
00042 dev_ctx_->get_stream(stream_id));
00043
00044
00045 int threads_per_blk = SHA1_THREADS_PER_BLK;
00046 int num_blks = (num_flows+threads_per_blk-1)/threads_per_blk;
00047
00048
00049 uint32_t *out_d = (uint32_t *)pool->alloc(20 * num_flows);
00050
00051
00052 char *in_d = (char *)memory_d + in_pos;
00053 char *keys_d = (char *)memory_d + keys_pos;
00054 uint32_t *pkt_offset_d = (uint32_t *)((uint8_t *)memory_d + offsets_pos);
00055 uint16_t *lengths_d = (uint16_t *)((uint8_t *)memory_d + lengths_pos);
00056
00057
00058 dev_ctx_->clear_checkbits(stream_id, num_blks);
00059
00060 if (dev_ctx_->use_stream() && stream_id > 0) {
00061 hmac_sha1_gpu(in_d,
00062 keys_d,
00063 pkt_offset_d,
00064 lengths_d,
00065 out_d,
00066 num_flows,
00067 dev_ctx_->get_dev_checkbits(stream_id),
00068 threads_per_blk,
00069 dev_ctx_->get_stream(stream_id));
00070 } else if (!dev_ctx_->use_stream() && stream_id == 0) {
00071 hmac_sha1_gpu(in_d,
00072 keys_d,
00073 pkt_offset_d,
00074 lengths_d,
00075 out_d,
00076 num_flows,
00077 dev_ctx_->get_dev_checkbits(stream_id),
00078 SHA1_THREADS_PER_BLK);
00079 } else {
00080 assert(0);
00081 }
00082
00083 assert(cudaGetLastError() == cudaSuccess);
00084
00085 streams[stream_id].out_d = (uint8_t*)out_d;
00086 streams[stream_id].out = out;
00087 streams[stream_id].out_len = 20 * num_flows;
00088
00089
00090 if (dev_ctx_->use_stream() && stream_id == 0) {
00091 sync(stream_id);
00092 }
00093 }
| bool sha_context::sync |
( |
const unsigned int |
stream_id, |
|
|
const bool |
block = true, |
|
|
const bool |
copy_result = true | |
|
) |
| | |
Synchronize/query the execution on the stream. This function can be used to check whether the current execution on the stream is finished or also be used to wait until the execution to be finished.
- Parameters:
-
| stream_id | Stream index. |
| block | Wait for the execution to finish or not. true by default. |
| copy_result | If false, it will not copy result back to CPU. |
- Returns:
- true if the current operation on the stream is finished otherwise false.
00098 {
00099 if (block) {
00100 dev_ctx_->sync(stream_id, true);
00101 if (copy_result && dev_ctx_->get_state(stream_id) == WAIT_KERNEL) {
00102 cutilSafeCall(cudaMemcpyAsync(streams[stream_id].out,
00103 streams[stream_id].out_d,
00104 streams[stream_id].out_len,
00105 cudaMemcpyDeviceToHost,
00106 dev_ctx_->get_stream(stream_id)));
00107 dev_ctx_->set_state(stream_id, WAIT_COPY);
00108 dev_ctx_->sync(stream_id, true);
00109 }
00110 if (dev_ctx_->get_state(stream_id) == WAIT_COPY) {
00111 dev_ctx_->sync(stream_id, true);
00112 dev_ctx_->set_state(stream_id, READY);
00113 }
00114 return true;
00115 } else {
00116 if (!dev_ctx_->sync(stream_id, false))
00117 return false;
00118
00119 if (dev_ctx_->get_state(stream_id) == WAIT_KERNEL) {
00120
00121 if (!copy_result) {
00122 dev_ctx_->set_state(stream_id, READY);
00123 return true;
00124 }
00125
00126 cutilSafeCall(cudaMemcpyAsync(streams[stream_id].out,
00127 streams[stream_id].out_d,
00128 streams[stream_id].out_len,
00129 cudaMemcpyDeviceToHost,
00130 dev_ctx_->get_stream(stream_id)));
00131 dev_ctx_->set_state(stream_id, WAIT_COPY);
00132
00133 } else if (dev_ctx_->get_state(stream_id) == WAIT_COPY) {
00134 dev_ctx_->set_state(stream_id, READY);
00135 return true;
00136
00137 } else if (dev_ctx_->get_state(stream_id) == READY) {
00138 return true;
00139
00140 } else {
00141 assert(0);
00142 }
00143 }
00144 return false;
00145 }

 1.6.3
1.6.3