
We have partially released the source code used in this work. You can find the user-level packet I/O engine for Intel 82598/82599 NICs here. We do not have a definite release plan for other parts of the PacketShader code not made available on the web as of today.
What is PacketShader?
PacketShader is a high-performance PC-based software router platform that accelerates the core packet processing with Graphics Processing Units (GPUs). Based on our observation that the CPU is the typical performance bottleneck in high-speed sofware routers, we scale the computing power in a cost-effective manner with massively-parallel GPU. PacketShader offloads computation and memory-intensive router applications to GPUs while optimizing the packet reception and transmission path on Linux. With extensive batch processing and pipelining, PacketShader achieves an unprecedented IP packet forwarding performance of 40 Gbps on an eight-core Nehalem server even for 64-byte packet size.
Why GPU?
As you all know, GPU is a central chip in your graphics card. GPUs expose a high level of processing parallelism by supporting tens of thousands of hardware threads and ample memory bandwidth. Beyond fast graphics rendering, recent GPUs are widely used for high-performance parallel applications whose workloads require enormous computation cycles and/or memory bandwidth. The data-parallel execution model of GPU fits nicely with inherent parallelism in most router applications.
Packet I/O Optimization on Linux
We implemented high-performance packet I/O engine for user-level application. This project is being maintained separately, and the source code is publicly available now.
Currently-available Linux network stack is not optimized for high-performance IP packet processing, say, for multi-10G networks. For high-speed software routers and better utilization of GPUs, we optimize the packet I/O path in Linux with the following approach.
- Huge packet buffer: Instead of allocating metadata (sk_buff or skb) and packet data for each packet reception, PacketShader pre-allocates two circular buffers that can hold a large array of metadata and packet data. This greatly reduces the memory allocation/deallocation overhead for high-speed packet reception.
- Batch processing: PacketShader batch processes a group of packets at a time in the hardware, device driver, and even in the application layer. This amortize per-packet processing overhead.
- NUMA-aware data placement: PacketShader minimizes packet movement between local and remote memory in a Non-Uniform Memory Access (NUMA) system. Packets received by NICs are processed by its local CPU and memory.
- Multi-core CPU scalability: PacketShader takes advantage of receive-side scaling (RSS) to eliminate the lock contention in accessing the NIC queues. It also removes the false sharing problem with the CPU cache by aligning the start address of RX queue to the cacheline boundary. Finally, it removes the global NIC counter for statistics. These optimizations allow linear scalability for multi-core router systems.
With our packet I/O optimization, we are able to run the packet processing in the user level even for multi-10G router workloads.
Performance
Figure 1 shows the performance of our optimized packet I/O engine. RX+TX bars represent the case of no-op forwarding, which transmits a packet from a port to another port without further processing.

We have implemented four "router applications" based on the packet I/O engine: IPv4 forwarding, IPv6 forwarding, OpenFlow switch, and IPsec tunneling. The below four graphs compare the throughput of the CPU-only implementation and the GPU-accelerated implementation. The performance results clearly show the effectiveness of GPU for packet processing.
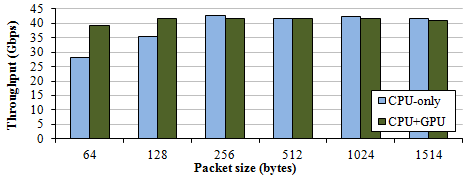
Figure 2. IPv4 forwarding
|
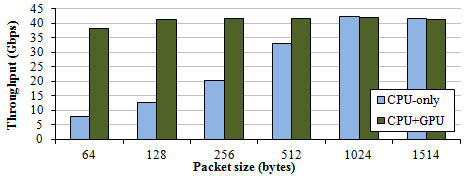
Figure 3. IPv6 forwarding
|
For the IP forwarding, we offloaded longest prefix matching to GPU. Forwarding table lookup is highly memory-intensive, and GPU can acclerate it with both latency hiding capability and bandwidth.
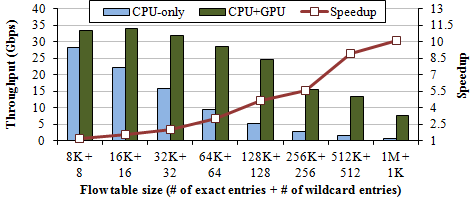
Figure 4. OpenFlow switch
|
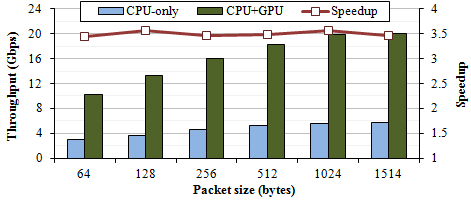
Figure 5. IPsec tunneling (AES-CTR and SHA1)
|
OpenFlow and IPsec represent compute-intensive workloads of software routers in our work. We have confirmed that compute-intensive applications can benefit from GPU as well as memory-intensive applications.
Current Status and Bottleneck
Our prototype implementation uses two four-core Intel Nehalem CPUs (2.66GHz), four dual-port 10GbE Intel NICs, and two NVIDIA GTX 480 cards. Since we use many PCI-e devices, our machine adopts two IOHs (formerly called Northbridge). Interestingly, the performance of our system is limited by the dual-IOH capacity. Specifically, we see asymmetric performance between the host-to-device and device-to-host PCI-e throughputs (more detail in our SIGCOMM paper below). Due to this problem, our current system cannot produce more than 40 Gbps performance even if both CPU and GPU are not the bottleneck.
Press Coverage
Publications
-
PacketShader: a GPU-accelerated Software Router (slides)
Sangjin Han, Keon Jang, KyoungSoo Park and Sue Moon.
In proceedings of ACM SIGCOMM 2010, Delhi, India. September 2010. -
Buildling a Single-Box 100 Gbps Software Router
Sangjin Han, Keon Jang, KyoungSoo Park and Sue Moon.
The 17th IEEE Workshop on Local and Metropolitan Area Networks (LANMAN) invited paper, Long Branch, New Jersey, May 2010. -
PacketShader: Massively Parallel Packet Processing with GPUs to Accelerate Software Routers
Sangjin Han, Keon Jang, KyoungSoo Park and Sue Moon.
USENIX NSDI poster, San Jose, California. April 2010.
People
Students:
Sangjin Han and
Keon Jang
Faculty:
KyoungSoo Park and
Sue Moon
We are collectively reached by our mailing list: tengig at an.kaist.ac.kr.